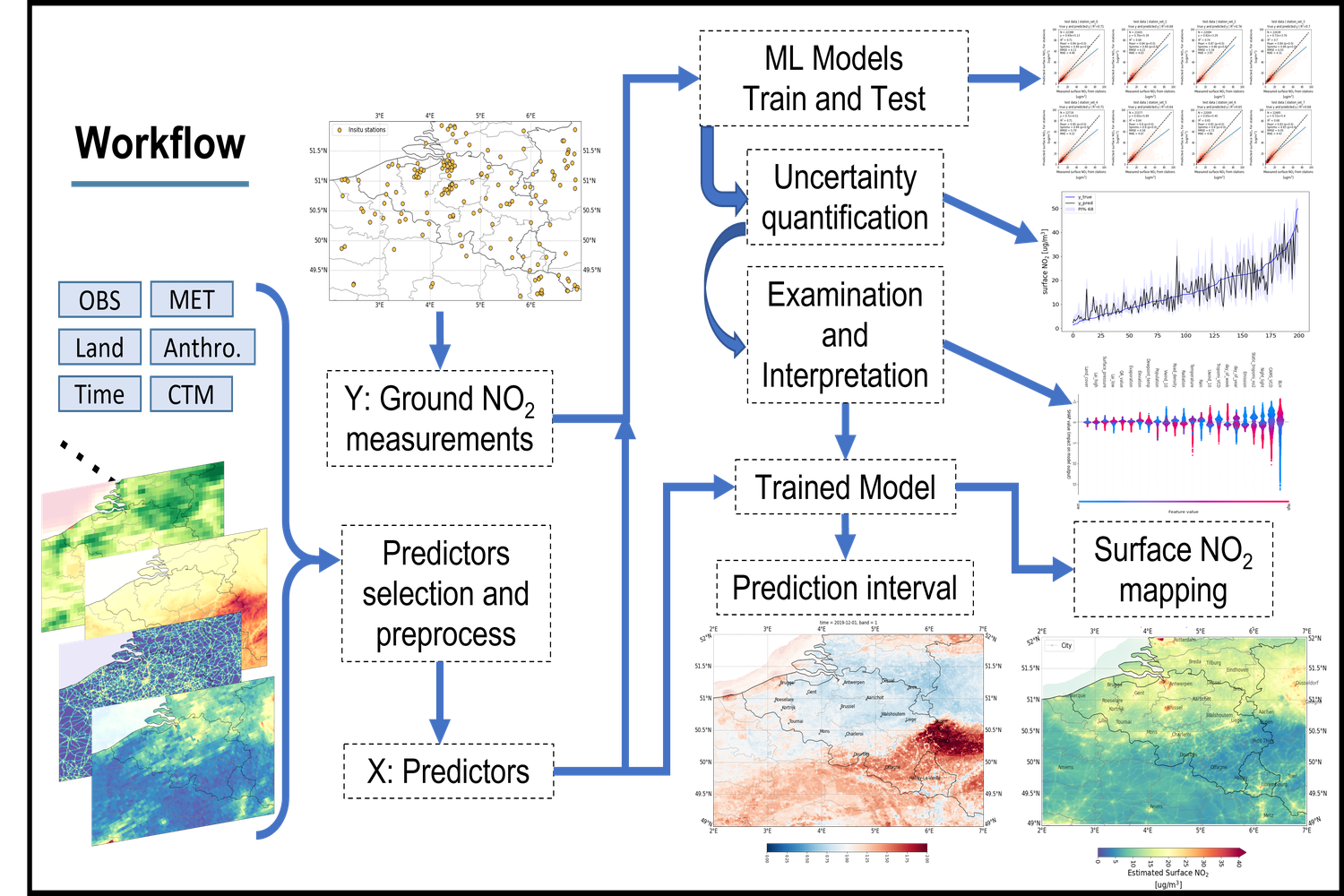
Body text
Het afleiden van NO2-oppervlakteconcentraties uit atmosferische kolommen, die door satellieten worden waargenomen, is van essentieel belang voor de beoordeling van de luchtkwaliteit en gezondheidsrisico's. Dit vereist de constructie van een model dat gebruik maakt van satelliet- en grondwaarnemingen en andere aanvullende data zoals meteorologische gegevens. Doorgaans wordt dit uitgevoerd met behulp van fysische modellen (die waarnemingen assimileren) of empirische statistische modellen. Deze modellen moeten afwegingen maken tussen rekenefficiëntie, resolutie en nauwkeurigheid.
Dit probleem wordt vereenvoudigd door machine learning (ML), dat een superieur vermogen heeft om complexe niet-lineaire koppelingen tussen variabelen en doelen te construeren. Met de snelle ontwikkeling van rekenkracht en big data is ML inmiddels op grote schaal bestudeerd en toegepast in diverse disciplines.
Momenteel is in vele studies aangetoond dat ML in staat is de spatiotemporele verdeling van NO2 met hoge resolutie te schatten. Het blijft echter een uitdaging om ML te gebruiken voor de productie van NO2 oppervlakteproducten vanwege de onstabiele voorspelling en het gebrek aan methodes om de onzekerheden van deze techniek te beoordelen.
Voor operationele retrieval van NO2-producten op basis van ML
Ons onderzoek heeft tot doel de volgende uitdagingen aan te gaan en een systematisch en praktisch schema te ontwikkelen voor de operationele retrieval van NO2-producten op basis van ML, in het kader van het project Terrascope. Dit onderzoek is lopende en het onderzoeksschema wordt hieronder uiteengezet:
- Identificeren van belangrijke voorspellers en onderzoeken van de geschikte gegevensverwerkingsmethode
- Onderzoeken van het gedrag en de prestaties van verschillende ML-modellen.
- Ontwikkelen van methoden voor het kwantificeren van de onzekerheid van ML-modellen.
- De betrouwbaarheid van de modelresultaten onderzoeken en interpretatie van de modelresultaten.
- Gezondheidseffecten beoordelen op basis van de modelvoorspelling.
- Het met ML gegenereerde NO2-oppervlakteproduct publiek toegankelijk maken.
- Algoritmen en schema's testen op het Belgische domein en de studie uitbreiden naar andere Europese landen.
In het algemeen beoogt deze studie te onderzoeken hoe ML-modellen de voorspelling van NO2-oppervlakteconcentraties kan verbeteren en overeenkomstige producten kan opleveren, hetgeen een perspectief zou bieden voor praktische toepassingen van ML-methoden in de atmosfeerwetenschap. Voorts verwachten wij dat de ontwikkelde methodes en modellen verder kunnen worden benut voor de voorspelling van andere atmosferische componenten.